Couchbase Server 4.5's new Sub-Document API
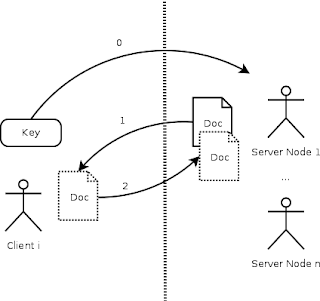
Introduction The Beta version of Couchbase Server 4.5 has just been released, so let's try it out! A complete overview of all the great new features can be found here: http://developer.couchbase.com/documentation/server/4.5/introduction/intro.html . This article will highlight the new Sub-Document API feature. What's a sub-document? The following document contains a sub-document which is accessible via the field 'tags': So far With earlier Couchbase versions (<4.5) the update of a document had to follow the following pattern: Get the whole document which needs to be updated Update the documents on the client side (e.g. by only updating a few properties) Write the whole document back A simple Java code example would be: Now with 4.5 The new sub-document API is a server side feature which allows you to (surprise, surprise ...) only get or modify a sub-document of an existing document in Couchbase. The advantages are: Better usabil