Large-scale data processing with Couchbase Server and Apache Spark
I just had the chance to work a bit with Apache Spark. Apache Spark is a distributed computation framework. So the idea is to spread computation tasks to many machines in a computation cluster. The idea here is to load data from Couchbase, process it in Spark and store the results back to Couchbase. Couchbase is the perfect companion for Spark because it is capable to handle huge amounts of data, provides a high performance (hundreds of thousands ops per second / sub-milliseconds latency) and is horizontally scalable by also being fault tolerant (replica copies, failover, ...).
You might already know Hadoop for this purpose. Sparks approach is similar but different ;-). In Hadoop you typically load everything into the Hadoop distributed file system and then let process it 'co-located' in parallel. In Spark each worker node is processing the data by default in memory. Your data is described by a R(esilient) D(istributed) D(ataset). Such an RDD is in the first step not the data itself. It is more describing from where the data is coming and which kind of data is expected to be processed. The RDD API is also describing how data can be processed (actions, transformations). In the next step the data is retrieved based on this description, whereby it is distributed across multiple workers (executors). RDD-s are not just sharded across the cluster, it is also possible to replicate them for fault tollerance.
Just in case that you don't know Spark, here the components of the Spark stack:
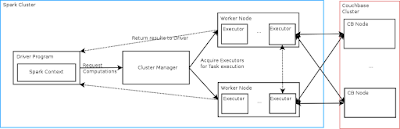
The following diagram shows the main architecture of a Spark cluster:
So what can we do with Couchbase? The following simple code example (Scala) shows how to read some keys from the database, filter based on the country, log them to the console and count. Finally the driver is storing back the result to Couchbase.
You can also store the RDD-s directly to Couchbase by using 'rdd.saveToCouchbase()'. Here an example from Couchbase's documentation:
The following very simple example shows how to retrieve data via SparkSQL:
And finally, here a streaming example which retrieves a micro-batch every second:
The example source can be found here: https://github.com/dmaier-couchbase/cb-spark-example . It also provides the helper 'Contexts' which I used in order to initialize and access the Spark context.
It's clear that this blog post was just a very brief introduction to Spark. Further, more use case focused, articles will follow. :-)
Further examples can be found in Couchbase's documentation: http://developer.couchbase.com/documentation/server/4.1/connectors/spark-1.0/spark-intro.html .
You might already know Hadoop for this purpose. Sparks approach is similar but different ;-). In Hadoop you typically load everything into the Hadoop distributed file system and then let process it 'co-located' in parallel. In Spark each worker node is processing the data by default in memory. Your data is described by a R(esilient) D(istributed) D(ataset). Such an RDD is in the first step not the data itself. It is more describing from where the data is coming and which kind of data is expected to be processed. The RDD API is also describing how data can be processed (actions, transformations). In the next step the data is retrieved based on this description, whereby it is distributed across multiple workers (executors). RDD-s are not just sharded across the cluster, it is also possible to replicate them for fault tollerance.
Just in case that you don't know Spark, here the components of the Spark stack:
- Spark Core: Handle RDD-s from several sources (and store them to several targets); So you could easily combine the data from several data sources with the data in Couchbase in order to derive new data which can then be stored back to your Couchbase bucket.
- Spark SQL: Handle data frames (RDD-s with a schema) whereby retrieving them (e.g. from a database system) by using a SQL like query syntax; Couchbase has it's own SQL like query language (N1QL) and so the integration works like a charm.
- Spark Streaming: Handle D(iscrete)Streams (RDD-s as micro batches); Couchbase allows you to consume the D(atabase) C(hange) P(rotocol) stream in order to react on changes in a bucket.
- MLib: An algorithm package for machine learning (to solve e.g. classification-, cluster-, regression- problems)
- GraphX: Graph processing and graph-parallel computations
The following diagram shows the main architecture of a Spark cluster:

- Driver Program: Creates the Spark context, declares the transformation and actions on RDD-s of data and submits them to the Master
- Cluster Manager: Acquires executors on worker nodes in the cluster.
- Workers and their Executors: Execute tasks and return results to the driver
So what can we do with Couchbase? The following simple code example (Scala) shows how to read some keys from the database, filter based on the country, log them to the console and count. Finally the driver is storing back the result to Couchbase.
You can also store the RDD-s directly to Couchbase by using 'rdd.saveToCouchbase()'. Here an example from Couchbase's documentation:
The following very simple example shows how to retrieve data via SparkSQL:
And finally, here a streaming example which retrieves a micro-batch every second:
The example source can be found here: https://github.com/dmaier-couchbase/cb-spark-example . It also provides the helper 'Contexts' which I used in order to initialize and access the Spark context.
It's clear that this blog post was just a very brief introduction to Spark. Further, more use case focused, articles will follow. :-)
Further examples can be found in Couchbase's documentation: http://developer.couchbase.com/documentation/server/4.1/connectors/spark-1.0/spark-intro.html .
Comments
Post a Comment